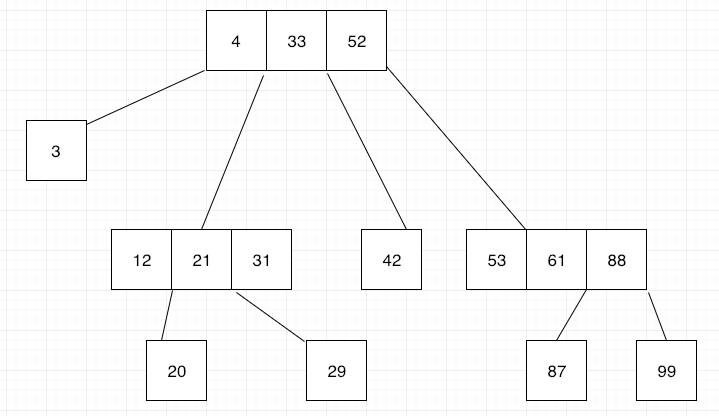
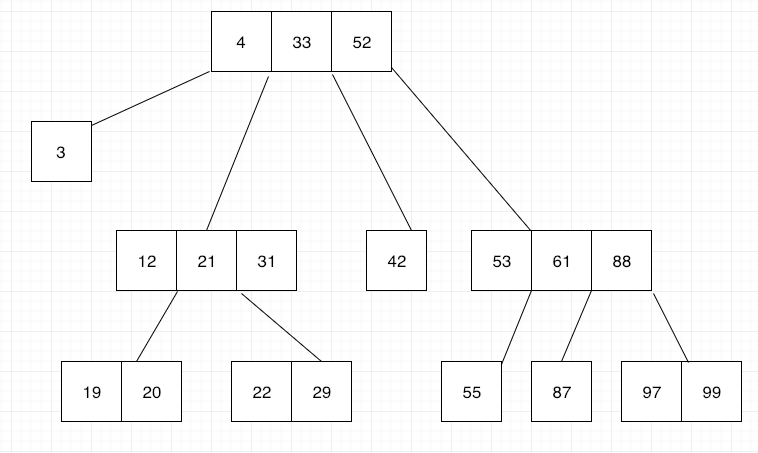
At some point we all worked with a relational database. We all had problems with query performance and we fixed them usually by first looking at indexes. We looked at the columns, at the foreign key for the presence of an index. We noticed there some kind of B-tree structure.
Now I’m gonna explain how this structure is being built.
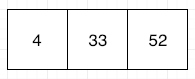
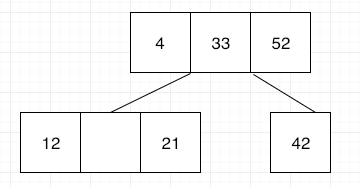
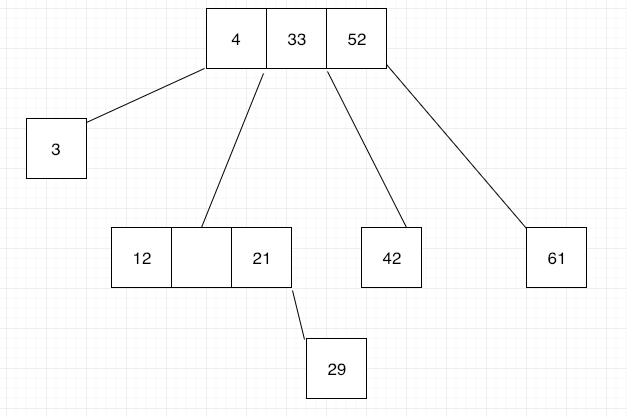
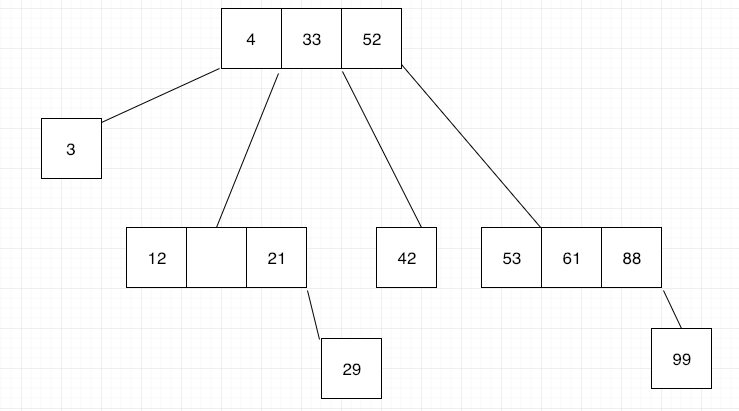
A B-tree starts with a root node, and within this node, you can store data records using their keys. These data records may have pointers to the actual value assigned to the key, or may have that value inside the data record. These records need to be found fast. To achieve this it’s important that the index keys in each node of a B-tree structure to be sorted.