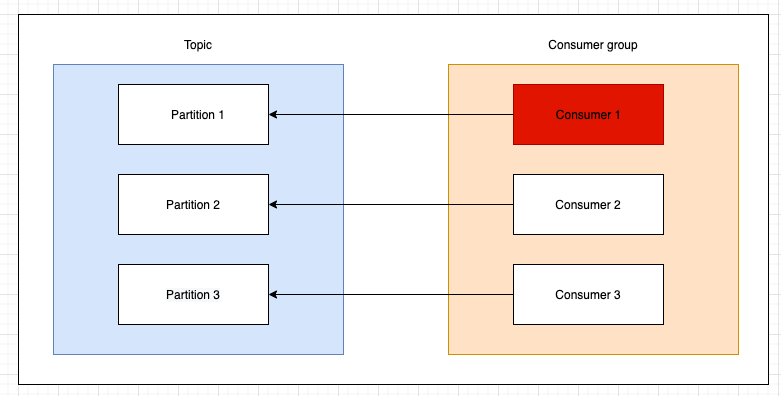
A consumer is a process that reads from a kafka topic and process a message. A topic may contain multiple partitions. A partition is owned by a broker (in a clustered environment). A consumer group may contain multiple consumers. The consumers in a group cannot consume the same message. If the same message must be consumed by multiple consumers those need to be in different consumer groups.
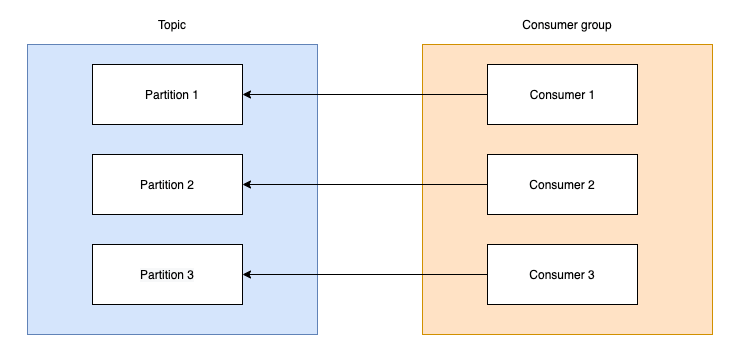
There is a tight relation between the number of partitions and number of consumers. In the above picture an ideal situation is described. If we have less consumers than partitions a consumer needs to read from multiple partitions affecting the throughput. If we have more consumers than partitions it means some of the consumers will be idle wasting processing power. Of course we cannot start with exactly the same number of partitions and consumers. Usually the number of partitions must be more than of consumers. Because we may not need that processing power at all times and we need to scale horizontally when needed. Hence we have the first situation when a rebalance is triggered.
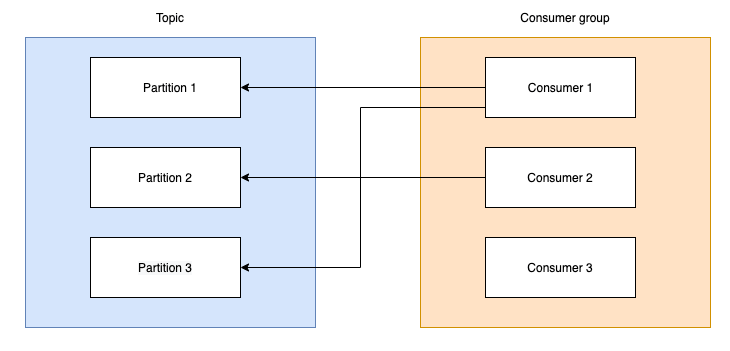
We must make the difference between group coordinator(one of the brokers) and group leader(one of the consumers). When we add a new consumer the group coordinator triggers a partition rebalance.
When a consumer wants to join a group, it sends a JoinGroup request to the group coordinator. The first consumer to join the group becomes the group leader. The leader receives a list of all consumers in the group from the group coordinator. After partition assignment, the group leader sends the list of assignments to the group coordinator, which sends this information to all the consumers. Each consumer only sees his own assignment, the group leader is the only consumer that see the other consumers in the group and their assignments.
That means the new consumer must get some work to do. Each partition has also offsets where it keeps the consumed messages indexes. The consumer updates these offsets and that action is called commit. The relation between partitions and offsets is kept in a special topic called __consumer_offsets. To not block the consumers that read and write to this topic it comes with an initial numbers of 50 partitions.
During the rebalance there is a stop-the-world short timeframe when no message will be consumed. We need to determine where does Consumer 2 starts consuming from. Before diving into the two scenarios that might happen we must take a step back and understand some consumer configurations.

It’s critical to note that with auto-commit enabled, a call to poll will always commit the last offset returned by the previous poll. Auto-commit always happens during poll() method and auto.commit.interval.ms only defines the minimum delay between commits.
| fetch.min.bytes | The minimum amount of data the server should return for a fetch request |
| fetch.max.wait.ms | The maximum amount of time the server will block before answering the fetch request if there isn’t sufficient data to immediately satisfy the requirement given by fetch.min.bytes |
| enable.auto.commit | If true the consumer’s offset will be periodically committed in the background. |
| auto.commit.interval.ms | The minimum delay in milliseconds that the consumer offsets are auto-committed to Kafka if enable.auto.commit is set to true |
| max.poll.records | The maximum number of records returned in a single call to poll(). |
| max.partition.fetch.bytes | The maximum amount of data per-partition the server will return |
With these configurations, when a new consumer is added the following situation might happen
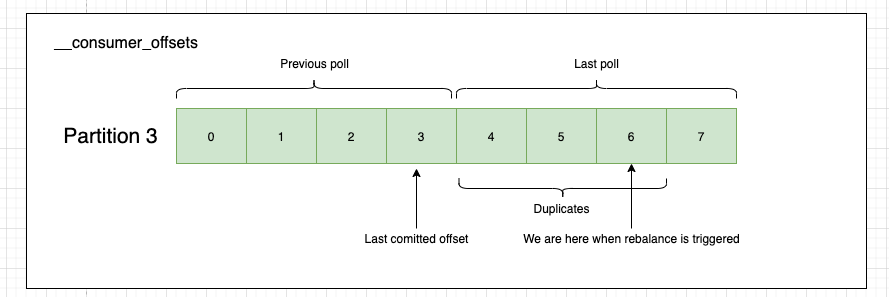
Let’s assume the new consumer(consumer 3) gets partition 3 (partition.assignment.strategy). The previous consumer (consumer 1) has committed offset 3(from previous poll) and was working on offset 6(current poll). The auto-commit interval did not pass, so no auto-commit was performed since message 3. The new consumer then looks for the last committed offset and find it at position 3. If if wouldn’t had found one, it would default to latest offset in the partition (auto.offset.reset). Obviously the new consumer will start from offset 3 meaning that offsets 4-6 will be reprocessed. We can fix this be implementing the idempotent receiver pattern.
Another situation that might happen is the following
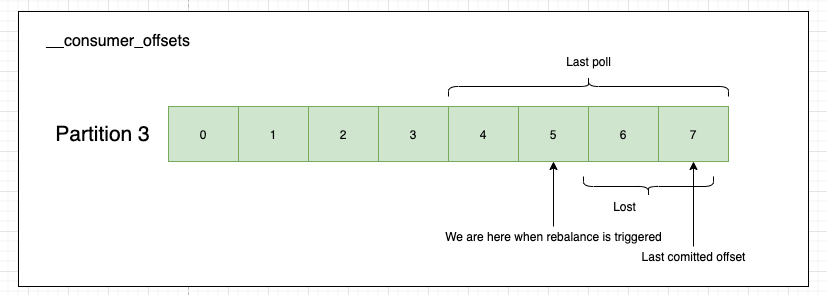
This is the worst place we can be in. The new consumer joins and see the latest offset is 7 (by doing a new poll()) and it will commit it, losing messages 6 and 7. How can we arrive in this situation? Well consumers think that once they pull the messages they are already processed. Put a slow consumer into equation and we get this. There is no relation between the success of the processing and the commit of an offset. Remember what we wrote above. With auto-commit enabled, a call to poll will always commit the last offset returned by the previous poll. We must ensure that all the messages are processed before calling poll again. If we don’t we could lose messages.
The tricky part here is that we make sure the message is processed no matter if with success or not. That means not all offset may be committed but that does not mean the message is lost. If properly handled it should be on the DLQ, for inspection or a later retry. This difference is important as we may lose the processing order guarantee.
That’s why auto-committing is dangerous and should be switched off.
These situations do not happen only when we scale up, but also when we scale down. Most importantly they may happen on exceptions that come from other services that we use. It’s time to look at other consumer configurations and see their impact.
| heartbeat.interval.ms | The expected time between heartbeats to the consumer coordinator when using Kafka’s group management facilities. |
| session.timeout.ms | The timeout used to detect client failures when using Kafka’s group management facility. Usually this is set to 3x heartbeat value. |
| max.poll.interval.ms | The maximum delay between invocations of poll() when using consumer group management |

Let’s say for example that consumer 1 executes a database query which takes a long time(30 minutes)
Now we don’t need to worry about heartbeats since consumers use a separate thread to perform these (see KAFKA-3888) and they are not part of polling anymore. Which leaves us to the limit of max.poll.interval.ms. The broker expects a poll from consumer 1 and since this is not going to happen it will consider it dead and will spawn a new consumer by triggering a rebalance. Remember that rebalance is a stop-the-world event and the relation between consumers and partitions may change.
The problem unfortunately won’t go away, because the the problematic database query will be picked up by another consumer and the situation will go on. We can “fix” this by increasing the max.poll.interval.ms to Integer.MAX_VALUE but we do want to fail fast so this is not a fix. The proper fix here is to implement a retry policy using a retry topic and a timeout. This will unblock the consumer avoiding a rebalance. It’s unlikely to perform better on a second retry if the problem is with a slow query. In these type of situations the messages will probably end in the dead letter topic. Or use a multi-threaded consumer.
For more details on consumer configurations check this. Kafka is a excellent machine, but if needs fine tuning and deep understanding.
