In the micro-services world, some rules must be respected:
-
Services must be loosely coupled so that they can be developed, deployed and scaled independently
-
Business transactions span across multiple services; they used data owned by multiple services
-
Queries must aggregate data owned by multiple services.
-
Different services may have different data storage requirements.
In one of this rule is broken you may not call that services a micro-service. In this post I wanna focus on the available strategies for managing data used by micro-services.
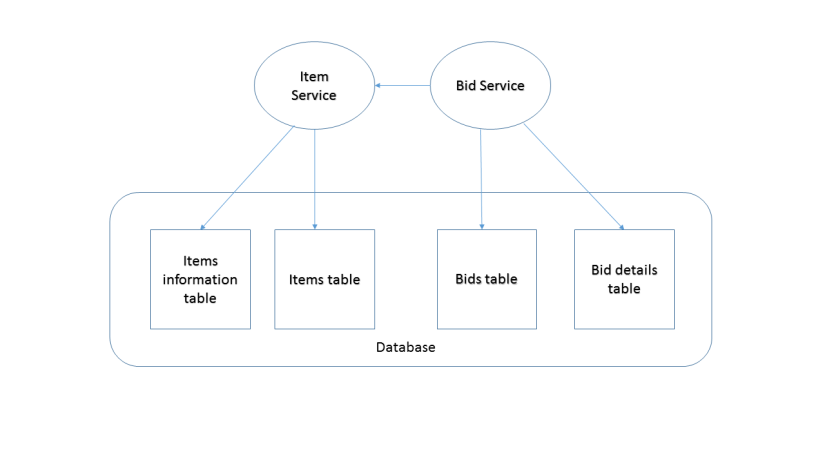
Shared database anti-pattern
This means that all services are using the same database. The main reason behind choosing this are the benefits of ACID. The transactions are atomic out of the box and you get consistency for free. Queries are a lot simplified as we have one database. The complexity is low for the same reason. But still it is an anti-pattern. The reason is obvious, it breaks the first rule of the micro-services: everything must be loosely coupled. Let’s take the case when two developers are working on the same database table. One might add a new relation by introducing a non-nullable foreign key without informing the other. Suddenly without touching the code the second developer notice that his micro-service does not work. What if the table is shared by 10 micro-services. Well it’s obvious what is gonna happen. Another drawback is if pessimistic locking is being used. Those other 9 services might need to wait for the lock to be released. Of course all of these can be avoided by using appropriate strategies, but still the dependency is there.
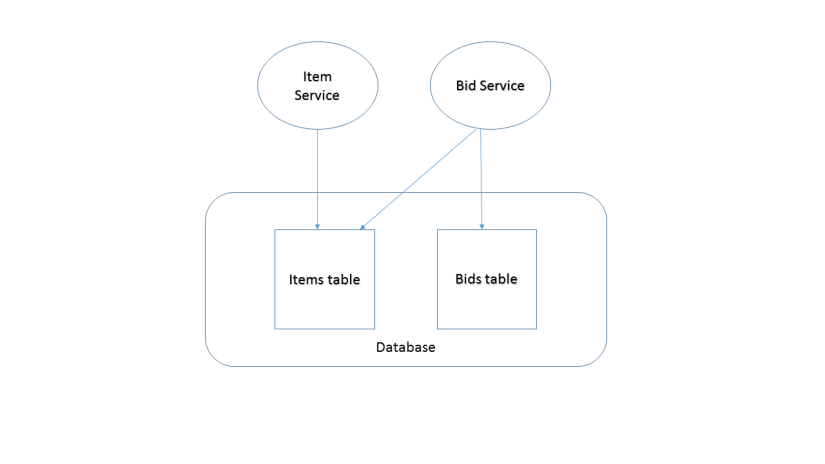
Shared database with private tables per service
This is an improvement from the above solution. Even though the same database is being used, the loose coupling is achieved by assigning a set of tables to a service. The tables must not be shared between services. ACID benefits are still present in the same set of tables. Discipline is required. The temptation to switch to the shared database anti-pattern is very high as one might lose the focus and rush things. The complexity remains at acceptable levels.
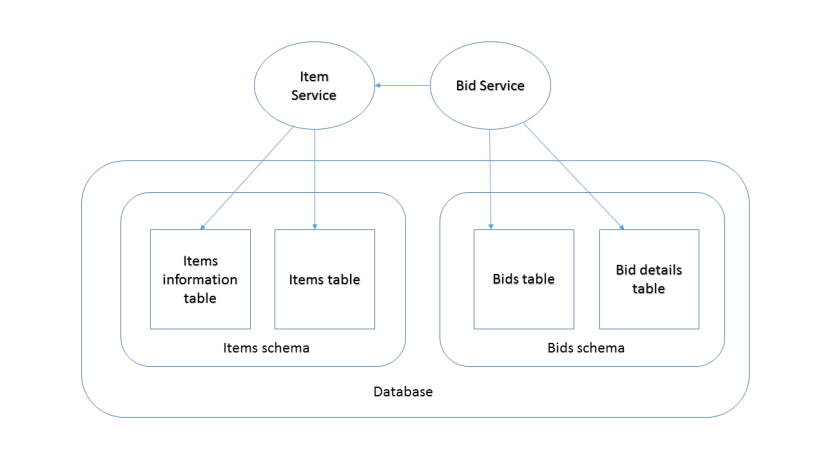
Shared database with schema per service
More cleaner. The schemas must not communicate directly. Ownership is clear. This is useful when you don’t want another database server for whatever reason. But this has its drawbacks. If for some reason the database server goes down, well it will trigger a chain reaction for services that use it. When using this you need to specify some clear limits or barriers to ensure no shortcuts can be taken and create more dependencies between services. You will notice I said more dependencies. We already have one. Same database server.
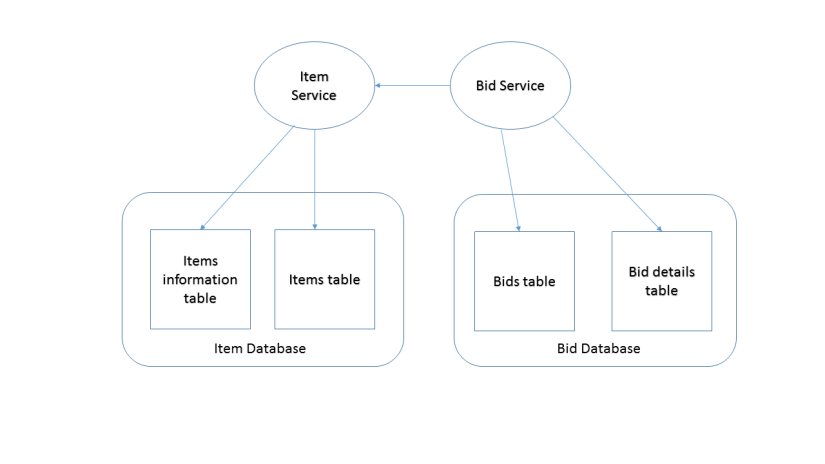
Database per service
It comes with the highest complexity. Transactions must be mimicked using events. Rollback must be defined and implemented explicitly. Consistency it’s hard to achieved. Queries are harder to implement. On the other hand this is the way to achieve truly low coupling. Going with this you can choose what database is suited for a service, there can by a mixture of RDBMS and NoSQL depending on the situation. This is what micro-services is all about.