In my previous post, I wrote about different strategies for managing data when using microservices. It’s obvious that the only solution is to go with database per service. But as already explained this comes higher complexity. Since we lost ACID, we will go with BASE (eventually consistent). Events will do the trick. If you worked with databases (I’m sure you do) you know there are queries, stored procedures, functions and…triggers. If you remember these triggers fired when an event happened on a resource that was listened on and they are doing some logic. Well something similar is happening in the microservice world.
In an event-driven architecture, a microservice publishes an event when something happens. Other microservices subscribe to those events and act accordingly. The subscribers can also produce events. The challenge is that every operation must be atomic.
We can achieve this by using distributed transactions (2PC) involving the database and the message broker, but the CAP theorem tells us we must choose between C and A, and availability is usually the best choice. Also distributed transactions come with a performance penalty which is hard to ignore. Fortunately for us there are another solutions.
Local transactions
This would mean that we need a event store. Whenever business objects change their state an event will be persisted in the store. This step is done in an atomic local transaction. Another process will listen for that event and it will publish it to the message broker. This is another local transaction. The main drawback is the tight coupling between events and business logic. Also the complexity is high. Just think about implementing transactions when using a NoSQL database. Sequence of events is also hard to maintain. Event duplication could be also an issue.

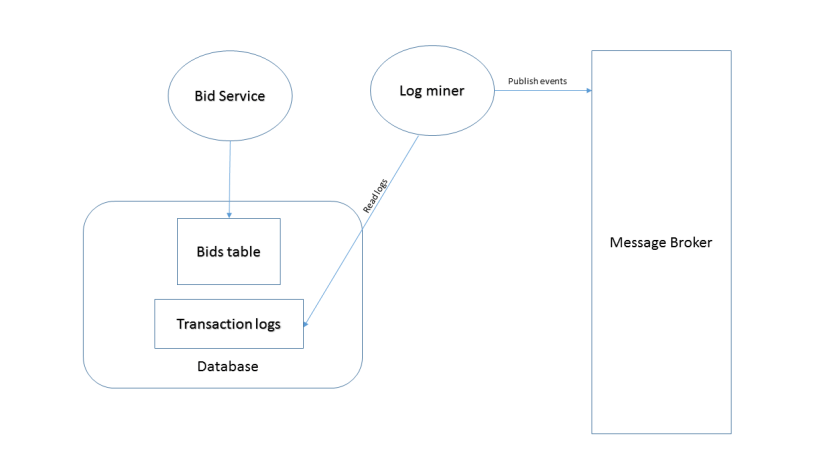
Database transaction log mining
Another way to achieve atomicity is to mine the database transaction log and publish events accordingly. It separates the event publishing from the business logic. You have the guarantee that the events are accurate. The problem here is that the log is database specific, so if you are using more than one database things could get tricky. Also reading a log is not something straightforward.
Event sourcing
Events take main stage in this one. They drive everything. Instead of storing the current state of the entity, the application stores the sequence of events that touched that entity. In this way the state can be easily reconstructed by replaying the sequence. Every change to the state means a new event added to the sequence. The events live in an event store, which acts also as a message broker. The most difficult part is querying the data and it involves implementing Command Query Responsibility Segregation (CQRS).

CQRS consits of two parts:
-
Command side which uses event sourcing and handles update requests
-
Query side which subscribes to events published by the command side and handles query requests
The command side transforms commands into actions, and actions into events which will be persisted in the event store. A command may generate events used by multiple microservices, which is useful is achieving referential integrity. Processed events generate materialized views which can be used for querying. The most important rule here is to make sure the query side is always read only. The views are kept synchronized with the changes by subscribing to events published by the command side.

These are some techniques for managing your distributed data. Choose the one which is appropriate for your situation.

1 thought on “Event-driven microservices”