The purpose of service discovery is like the name states to make the microservices discoverable. Their network locations should be dynamically assigned, as they could fail, become unresponsive and another instance should be there to perform the required work. These microservices should be highly-available.(CAP theorem). We need a service registry where the services should be registered and made discoverable.
Service registry
You can look at it like a cache or a database. It contains all the services that can be used along with their relevant data. Service instances register automatically when they are up, and unregister when the instance is destroyed. It provides an API for operations like register, unregister, listing available instances, etc. There should be a heartbeat mechanism in place to check periodically the services to make sure they are still up and running. The most notable service registries are consul, eureka, zookeeper and etcd. A comparison between some of these can be found here.
The service registry operations can be achieved either by following a self-registration pattern in which each service is responsible for implementing these operations, like eureka or by using a 3rd party pattern where a service registrar like registrator handles these operations. The latter decouples the service discovery from the service registry while the former couple them.
We can interact with the service registry in two ways: client-side discovery or server-side discovery.
Client-side discovery
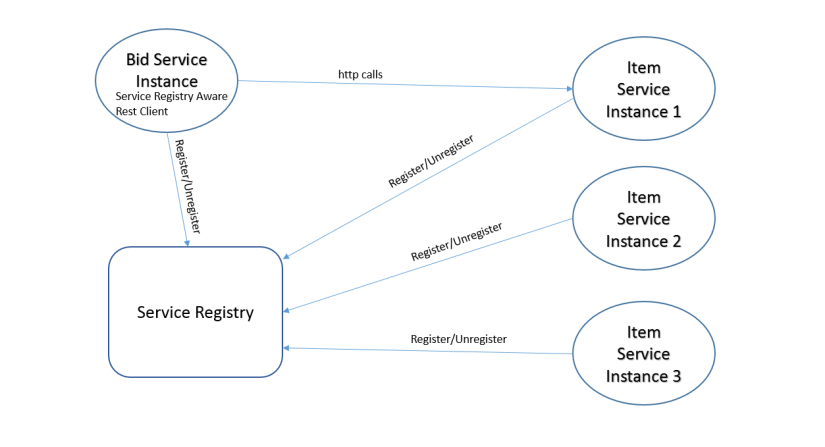
The client code is responsible for discovering the available services by querying the registry. The client is responsible for load balancing between instances. The problem is that the client is coupled to the service registry. On the other hand, client code must be implemented for each specific technology.
Server-side discovery
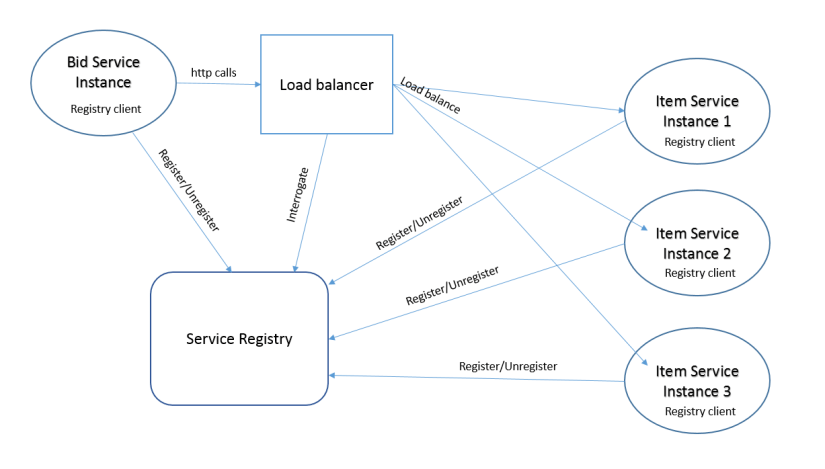
The load balancer is in control of the discovery, which eliminates the need for client discovery code. The bad part is that the load balancer must be managed, and we already have a bunch of services to manage. That is if it’s not offered out of the box from the cloud environment (see AWS Elastic Load Balancer).
