Microservices should respect the CAP theorem. That means when a failure occurs, you should choose between consistency and availability, and availability is the best choice. Hystrix has the role to keep the availability high when a partition occurs, by stopping cascading failures and providing fallback. These partitions should not be visible to the end user, he should be able to continue its work.
According to this we can take multiple actions when the partition occurs. Hystrix works like a glove for these.
@HystrixCommand(fallbackMethod = "getLatestItemsFromCache", commandProperties = {
@HystrixProperty(name = HystrixPropertiesManager.EXECUTION_ISOLATION_THREAD_TIMEOUT_IN_MILLISECONDS, value = "5000") })
This means Hystrix will wait this specified amount of time for a response. If the time elapses it will throw a HystrixRuntimeException.
We can limit the threads. If the server responds slow, that does not mean that requests won’t be send anymore to it. And since each request is a thread, we will end up with too many threads.
@HystrixCommand(fallbackMethod = "getLatestItemsFromCache", commandProperties = {
@HystrixProperty(name = HystrixPropertiesManager.QUEUE_SIZE_REJECTION_THRESHOLD, value = "5"),
@HystrixProperty(name = HystrixPropertiesManager.MAX_QUEUE_SIZE, value = "10")})
We can short-circuit the requests. When the server is down or it is at max capacity, we must stop the requests to it.
@HystrixCommand(fallbackMethod = "getLatestItemsFromCache", commandProperties = {
@HystrixProperty(name = HystrixPropertiesManager.CIRCUIT_BREAKER_ENABLED, value = "true"),
@HystrixProperty(name = HystrixPropertiesManager.CIRCUIT_BREAKER_SLEEP_WINDOW_IN_MILLISECONDS, value = "5000"),
@HystrixProperty(name = HystrixPropertiesManager.CIRCUIT_BREAKER_REQUEST_VOLUME_THRESHOLD, value = "1"),
@HystrixProperty(name = HystrixPropertiesManager.EXECUTION_ISOLATION_STRATEGY, value ="THREAD") })
In this example I’ve went and use a simple caching mechanism, in the case when the server fails data is taken from the cache. Some notes on the fallbackMethodName:
-
cannot be checked at compile time for existence
-
the signature of the original method must match the fallback method
Some more interesting things that Hystrix brings are the request cache which uses a per-request in-memory cache to prevent commands with the same argument from being made multiple times and the request collapser which batches requests before going on to the server.
Fallbacks makes sense in most situations except:
-
a command that performs a write operation; if it fails it makes no sense to implement a fallback but announce the user that the operation did not succeeded
-
long computation; if a report is generated asynchronous it would be a mistake to send incomplete or degraded data to the user
Our item query microservices look something like this.
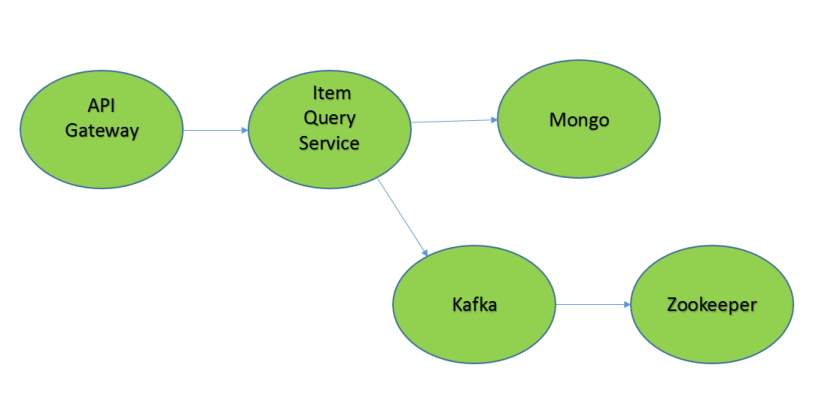
When the Item Query Service is not available, the user should still be able to use it. We create a fallback that will return data from a cache when a partition happens.
@HystrixCommand(fallbackMethod = "getLatestItemsFromCache", commandProperties = {
@HystrixProperty(name = HystrixPropertiesManager.EXECUTION_ISOLATION_THREAD_TIMEOUT_IN_MILLISECONDS, value = "5000") })
private ResponseEntity findAllItems() throws JsonProcessingException {
return itemViewFeignClient.findAllItems();
}
private ResponseEntity getLatestItemsFromCache() throws JsonProcessingException {
Collection latest = cacheService.getItemsFromCache();
return new ResponseEntity<>(objectMapper.writeValueAsString(latest), HttpStatus.OK);
}
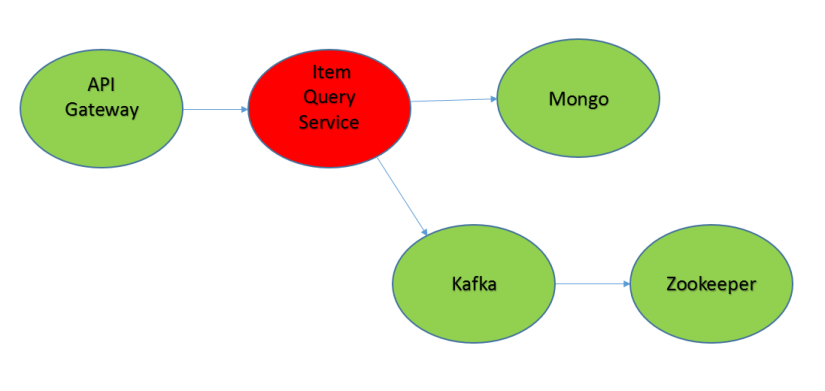
In order to replicate this we must enter some items. For example
[
{
"itemCode": "1",
"reservePrice": 400
},
{
"itemCode": "2",
"reservePrice": 400
}
]
These should be in cache at this point. Next step is to stop the item query service. For this just stop the docker instance. Now if we try to query for items, we should get some. Indeed you can see that you keep entering items and they are returned. From a user’s perspective there is no problem. But from a developer’s perspective a partition has occurred. Next step is to recover from it, without any impact on the user experience. A strategy is needed to copy the items from the cache to the actual persistence unit without duplication. This is beyond this post’s scope. You could have chosen a different strategy, for example to stop the creation of items if the retrieval service is down, with the items cache still working.
And there’s more. Hystrix has a dashboard where you can see what’s going on with your services. First of all we must start hystrix as a separate service and you’ve guessed it; it’s just another spring boot app.
@SpringBootApplication
@EnableHystrixDashboard
@EnableEurekaClient
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
Normally we should see

Next step is to feed a stream to hystrix. Turbine can do this if you have multiple applications that are guarded by hystrix. If not the hystrix.stream on your application will suffice.
@SpringBootApplication
@EnableTurbine
@EnableEurekaClient
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
If you have turbine enabled and you application is registered with it
turbine:
clusterNameExpression: new String('default')
appConfig: API-GATEWAY
you can monitor the stream by giving
http://turbine-hostname:port/turbine.stream
The other case is to use the hystrix.stream directly by accessing
http://hystrix-app:port/hystrix.stream
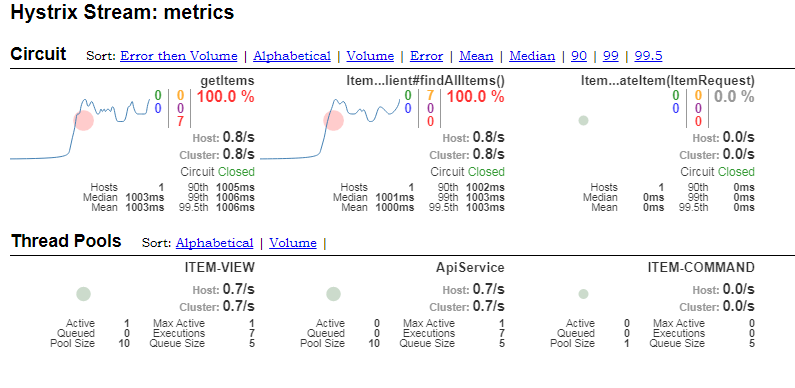
Going back to our failing example, the hystrix dashboard signals the failures. We can see that 7 failures have occurred.
We just scratched the surface. For more options and details go to Hystrix wiki.
SOURCE_CODE

2 thoughts on “Hystrix”