Also known as *ilities(scalability, deployability), NFRs(non-functional requirements), quality attributes. There is no fixed list of these. We do however have a standard for these. It’s ISO25010 and it looks like
We extract these from business requirements(business characteristics), from the way we expect to operate the system(operational characteristics) and they are implicit, cross-cutting characteristics which fall in the architect’s ability to read between the lines. This table from the Fundamentals of Software Architecture book will help in finding hidden characteristics.
| Domain concern | Architecture characteristics |
|---|---|
| Mergers and acquisitions | Interoperability, scalability, adaptability, extensibility |
| Time to market | Agility, testability, deployability |
| User satisfaction | Performance, availability, fault tolerance, testability, deployability, agility, security |
| Competitive advantage | Agility, testability, deployability, scalability, availability, fault tolerance |
| Time and budget | Simplicity, feasibility |
A good description of an architecture characteristic can be found in the Software Architecture in Practice book.
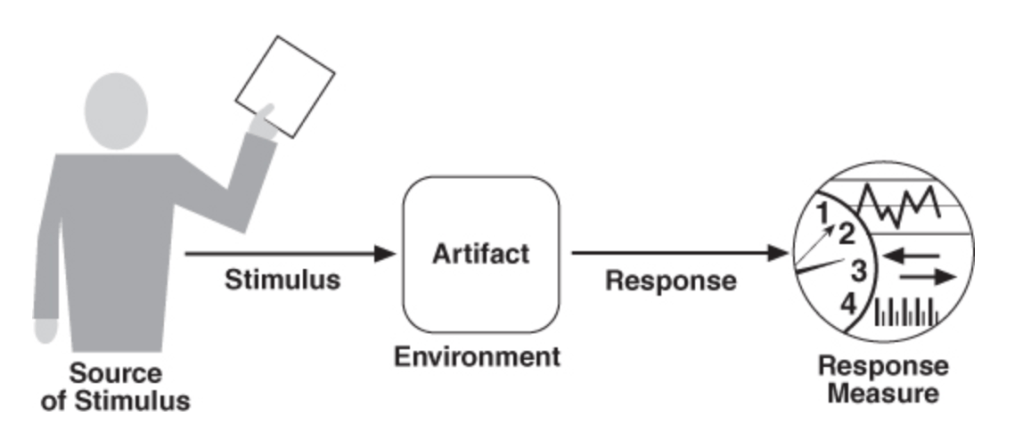
Source of Stimulus could be an actor, something that triggers an event, etc. The stimulus is the actual event produced. Environment represents the condition of the system where the event appeared. The artifact is the part of the system that is being stimulated. The response is the way the artifact behaves under that stimulus which we should measure. Given these guidelines we can start to look at some characteristics.
Performance
According to Smith “Performance refers to responsiveness: either the time required to respond to specific events or the number of events processed in a given interval of time”. We can measure performance by looking at
| Latency | Represents the time passed before we get a response. The focus is a period of time here. We have minimum latency(start time) and deadline(end time). Other factors of measuring latency are precedence(where we look at the order of responses) and jitter(latency fluctuations observed over time). |
| Throughput | Refers to the number of responses we get over a fixed interval of time. However we should not perform only one measure, but many in order to improve accuracy. |
| Usable capacity | This combines the above measures. The maximum achievable throughput without violating specified latency requirements. |
| Schedulable utilization | If utilization is the percentage of time a resource is busy, the schedulable utilization is the maximum utilization that satisfy the timing requirements. |
| Data miss | If caching is used to improve performance then cache misses become a performance measure. |
Techniques to improve performance
Before we look at these we must understand what may affect performance.
| Demand | How much resources do we need? |
| Hardware | What types of resources do we need? CPU, memory, I/O device, network. Is the system performing under normal conditions? Or is it under heavy load? |
| Software | Are the frameworks that we use efficient in terms of performance? Are they using buffers? Is some kind of reflection(java) involved? Are they tuned for maximum performance? |
We need to control demand. We can do this be using queues, throttling and backpressure mechanisms. By improving our algorithms we can reduce the demand of resources. By setting max response time(timeouts) and some kind of prioritization we can further control the demand.
We can use vertical scaling to get better response times. Concurrency is another way of improving performance. We need to be aware of Amdahl’s Law though

Limit you resources. Go with a fixed limit in production for everything(threads, queues). Schedule resources and avoid contention as much as possible. Easier said than done. Use caching judiciously. Scale horizontally to add multiple processing units.
Know your frameworks. Know your databases. Tune them.
Reliability
According to Oxford Dictionary reliable means consistently good in quality or performance; able to be trusted. Reliability can be characterized in terms of mean time between failures (MTBF), with reliability = exp(-t/MTBF).
But when it comes to put some numbers we may struggle. There is no clear way of doing it. We may use software metrics as cyclomatic complexity and code coverage to get some idea about the edge cases. Also fitness functions could be used to measure reliability. The number of open issues, number of successful builds and deployments may help. Achieving ISO-9001 can be another way to measure it.
Techniques to improve reliability
Since we cannot really measure it, how can we improve it? Well it turns out by following best engineering practices will results in better products. Higher reliability can be achieved by using better management practices, better processes. The use of mutation testing techniques will let the system to think of edge cases. Chaos testing is another great tool of increasing reliability. Use Akin’s Laws of Spacecraft Design as guidance. Make your system antifragile.
Availability
Represents the ratio of the available system time to the total working time. It’s another layer on top of reliability. It’s the ability of a system to mask or repair faults within certain thresholds(eg time intervals). Availability can be expressed as
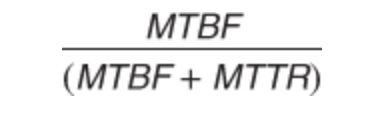
Using it we get to the nines table.
| 99% | 3 days and 15.6 hours per year |
| 99.9% | 8h and 56 seconds per year |
| 99.99% | 52 minutes and 34 seconds per year |
| 99.999% | 5 minutes and 15 seconds per year |
| 99.9999% | 32 seconds per year |
| 99.99999% | 3 seconds per year |
Techniques to improve availability
In order to improve it, first we need to detect the possible faults.
| Monitor | Watch over different parts of the system like CPU, memory |
| Heartbeat | Regular checks of the system to ensure everything is up and running. |
| Timestamps | Events should have timestamps associated, in order to reproduce different scenarios. |
| Exceptions | Exceptional situations which we do not foresee. |
| Timeouts | We set limits of the maximum allowed time to produce a response. |
After we detected an abnormal situation, we can intervene by.
| Hot redundancy | This means we are working in a clustered environment, and when one component goes down, the cluster will intervene and continue to work. |
| Warm redundancy | A master slave relation is involved here. The redundant component does nothing, just sits there. But in eventually receives all changes from the master component and can take its place in matter of milliseconds. |
| Cold redundancy | A new brand instance of that component is being spawned when certain conditions are met. This will however mean that downtime exists, so it’s not recommended to be used in highly available systems. |
| Exception handling | Depending of type we can use retry mechanisms, caching. |
| Retry mechanisms | We should use these under the assumption that the dependent system may become available on a subsequent retry. |
| Rollbacks | The ability to get back the system to a previously working state. |
Resiliency
Represent the system’s ability to function when facing with problems that cause it to fail, by degrading its services until a fix in is place, but with no interruptions of those services. In order to achieve this defence capabilities must be put in place(Circuit Breaker pattern). Resiliency is sometime referred as fault tolerance. Faults are tolerated because they are detected and proper measures can be taken. A resilient system is one which when put under pressure adapts to ensure its survivability. As in case of reliability it’s hard to put numbers on resiliency.

Techniques to improve resiliency
First thing is to identify the potential risks. What are the critical functions that the system must perform no matter what? What pieces of hardware are vital? Then we need to implement protection strategies. In doing this we need to look at what events may cause those vital parts to fail. Once detected tolerance thresholds must be chosen. What is our maximum tolerance level? Some examples of protection strategies may include imposing a limit on number of requests, on number of threads, cache same requests, send requests in batches.
Dependability
This is holistic view which describes how dependable is the system. It includes reliability, availability, resiliency, continuity(availability/resiliency function), recoverability(resiliency function), robustness(reliability function). Even though the differences are subtle between these, we should always consider them as a whole.
For example if we think of a car we can say that car is reliable if it’s new and it’s make is known for reliability(eg Mercedes). Availability is satisfied by the fact we have a spare tire, though it’s not high availability. Resiliency can be though of a situation when we 4 wheel driving fails, but we still have 2 wheel driving(we experience a degradation). Continuity can be thought in terms of both availability(we have the spare tire to continue) and resiliency(we can continue with 2 wheel driving). When we say robustness think of a bumpy road. Do we feel the car is disintegrating of that road or we feel the ride is still comfortable? If our car is electric we may consider recharging as we drive a recoverability function.
Scalability
Is the property of a system to perform within acceptable thresholds under heavy load. There is manual scalability when we manually scale(eg 1+1 redundancy) from the start. Also there is automatic scalability characterized by volatility. This is called elasticity. When bursts in load are encountered the system reacts and scales horizontally(adding/removing more instances of itself). We can observe these bursts by looking and CPU and memory. After these burst are finished the system kills the unnecessary instances reducing costs. When we scale vertically means that we add more physical resources to the system (eg more memory, better cpu).
Techniques to implement scalability
Well this falls back in the devops area and it’s better to use a cloud service like aws fargate to get them easily. In the following picture you can see both the scale up and down policies.
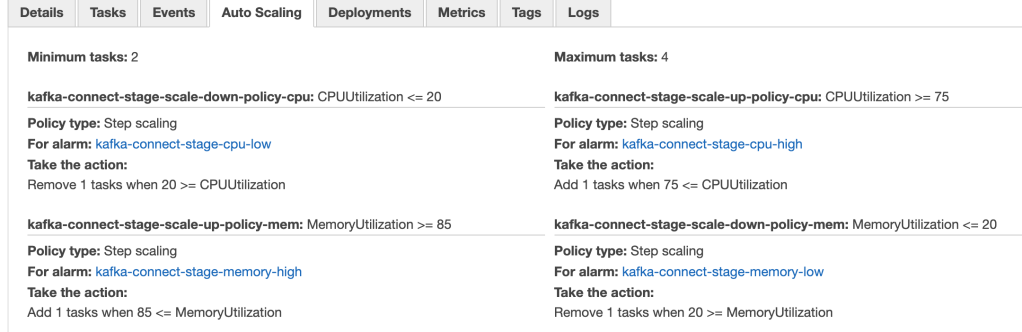
Security
It’s actually a conglomerate of characteristics. Confidentiality refers to the ability of a system to keep user’s data safe. Integrity is the ability to protect outside sources from tampering with it. Authentication allows the user to access the system and authorization tells the user which parts of the system he can access. Authorization is usually implemented using RBAC, ACL or ABAC. Nonrepudiation guarantees that the sender of a message cannot later deny having sent the message, and that the recipient cannot deny having received the message.

Techniques to improve security
We need to detect first.
| Signature Based Detection | Check service requests pattern against a set of signatures or known patterns of malicious behaviour previously stored. |
| Anomaly Based Detection | By storing customer’s behaviour we can detect when something out of the ordinary happens. This task is not trivial as it requires huge sets of data. |
| Verify message integrity | Sign messages with checksums or hashes. A change in those values means there is a problem. |
| Detect man-in-the middle | By using timestamps in the messages it’s possible to detect abnormal behaviour(eg a message takes longer to arrive than usual) |
If however an attack goes through, we need to have a strategy in place for reacting. This depends from a situation to another. In most cases we can revoke the access but in some extreme cases we can shutdown the system. Of course it’s always better to prevent that fix. Some prevention tactics can be found in my previous article on security. The best advice here is to use existing security solutions, it’s almost all cases it’s a bad idea to implement it ourselves.
Interoperability
This represents the ability of the system to communicate with external systems. The most important aspect of this is to understand the contract interfaces. Once we understand these we can cover all aspects of communications including error handling. Of course this is not a trivial job.
Techniques to improve interoperability
The best tactic here is the use of Enterprise Integration Patterns. If multiple communication protocols are involved, this is the best way to prepare for those situations.
Modifiability
Also referred as changeability. Describes how easy or hard is the system able to change. Usually this is an implicit characteristic. As architect you need to always take into account the fact that the probability of change is unknown, but when(not if) the time comes the system should be able to accept that change gracefully. Change is the only certainty if the software world. Having said this we cannot design the whole system as a parts of changeable components. If every component will be a plug and play component we might not ever finish the design. So we need to find those parts whose likeliness to change is high.

Techniques to improve modifiability
These have two dimensions. As an architect, you need to determine what are those parts that have a higher chance of changing. As a software engineer you must make sure those parts are easy to change. Following SOLID principles is a great start. Measure afferent and efferent coupling using fitness functions. We need to calculate the cost of change. For example if we build a UI form which we need in more places than initially thought, we could either copy paste the code and make necessary adjustments or we could build a new component and put that in place. We then get the cost of change
N x writing the code (copy paste) <= writing the component + (N x putting it in place)
Time also must be included. The observations must be made during a medium to long period of time.
Deployability
All systems should be encapsulated in some kind of artefact. That can be war, jar, ear, apk, dll, gem, etc. These are deployed in an environment that is capable of running those. Since docker this has been greatly improved, now we can have multiple environments on one machine. Deployability is the mechanism that transforms the code into useable products for the customer.
Techniques to improve deployability
The most efficient thing we can do here is to implement Continuous Integration/Continuous Deployment (CI/CD). If we are religious that would mean that each code push will trigger a production deployment. In order to do this your code should be guarded by fitness functions and automation tests. This is an important part of antifragility. Now is most cases(unless you’re google or facebook) this is not needed. But we do want to do deployments on demand and a single push of a button should be sufficient. As in all things we do want to avoid ceremony and go straight to the essence. But we also deploy hardware, not just software. Using techniques as infrastructure as code will speed things up.
Testability
An important aspect of every system. We must ensure the system was build in order to respect the needs of the customer. A complex system is hard to test. Take for example a microservices architecture where we have lots of moving parts that may evolve individually. This characteristic is often compromised to others. For a system to be testable we need to be able to control the input and output of each component.

Techniques to improve testability
Limit the complexity of the system if that is possible. Build smaller components and try to not reinvent the wheel. Write testable code, apply TDD where appropriate.
Simplicity
This is hard to achieve. Everything is a trade-off and in most cases this is a sure loser. But if we need to build something fast in a limited timeline then this is a winner. When building MVP(minimum viable product) all we care about is simplicity. But careful here. We should not throw everything after we achieved our goal. Not to be confused with POC(proof of concept) or some kind of R&D. Reusability is also important here.
Techniques to improve simplicity
Build coarse-grained components. Use RAD frameworks like Apache Isis, Vaadin or JHipster. Make sure the you can live with the trade-offs you made here before making them. Follow KISS principle. Remember that time is key here and eventually(and hopefully) you will have time to make it better. Make it work, you can make it pretty and fast later.
Portability
The ability of a system to port from a OS to another. This impacts the programming language choice. For example we know that in order to run java code we need a JVM, so the question we need to ask is “Is JVM portable?”. And the answer is yes. Another example would be golang. This is packaged as a binary, no external dependencies are needed so it is portable. We encounter problems when we do need microsoft tech. These need a microsoft OS in order to run, which limit their portability.
Techniques to improve portability
Well there is one obvious choice. Use containerization. Use docker. A docker engine is capable of running multiple docker containers hiding the implementation details. And there are Windows containers out there.
Usability
This is a holistic view. When we talk about usability we usually mention configurability, which is the users’s ability customize the system, whether it’s by changing the look and feel through UI themes or configuring the behaviour of the system like controlling user access, etc.

Localization, also know as i18n(internationalization) is mentioned as well. The ability of a system to support multiple standards. Usually this is implemented through User Experience(UX). When I say standards I refer to language, currencies, metric units, character encodings. The localization resources are usually static.
Accessibility is another aspect of this. Unfortunately there are persons in this world with disabilities(blindness, hearing loss, color blindness). How can we make sure these persons can benefit from the advantages of our system? The color choice will go great lengths for the color blind. Siri/Alexa is a great example for the ones whom are not able to see. Think of our grandparents when designing for accessibility.
It’s not uncommon for a system to have some kind of help page or even a support person available at all times. This is supportability. We should strive to make the system intuitive and easy to use. This affects learnability, which is the time needed for a user to be comfortable with using the system. Strategies like users training and help pages will be effective.
Extensibility
A system characteristic that describes how important is to have plug-and-play components. It’s required for systems that have kernel like architectures. Classic examples of this are Eclipse Platform and OSGI standard.
Antifragility
Is a property of systems that increase in capability to thrive as a result of stressors, shocks, volatility, noise, mistakes, faults, attacks, or failures. Since a picture is like a thousand words
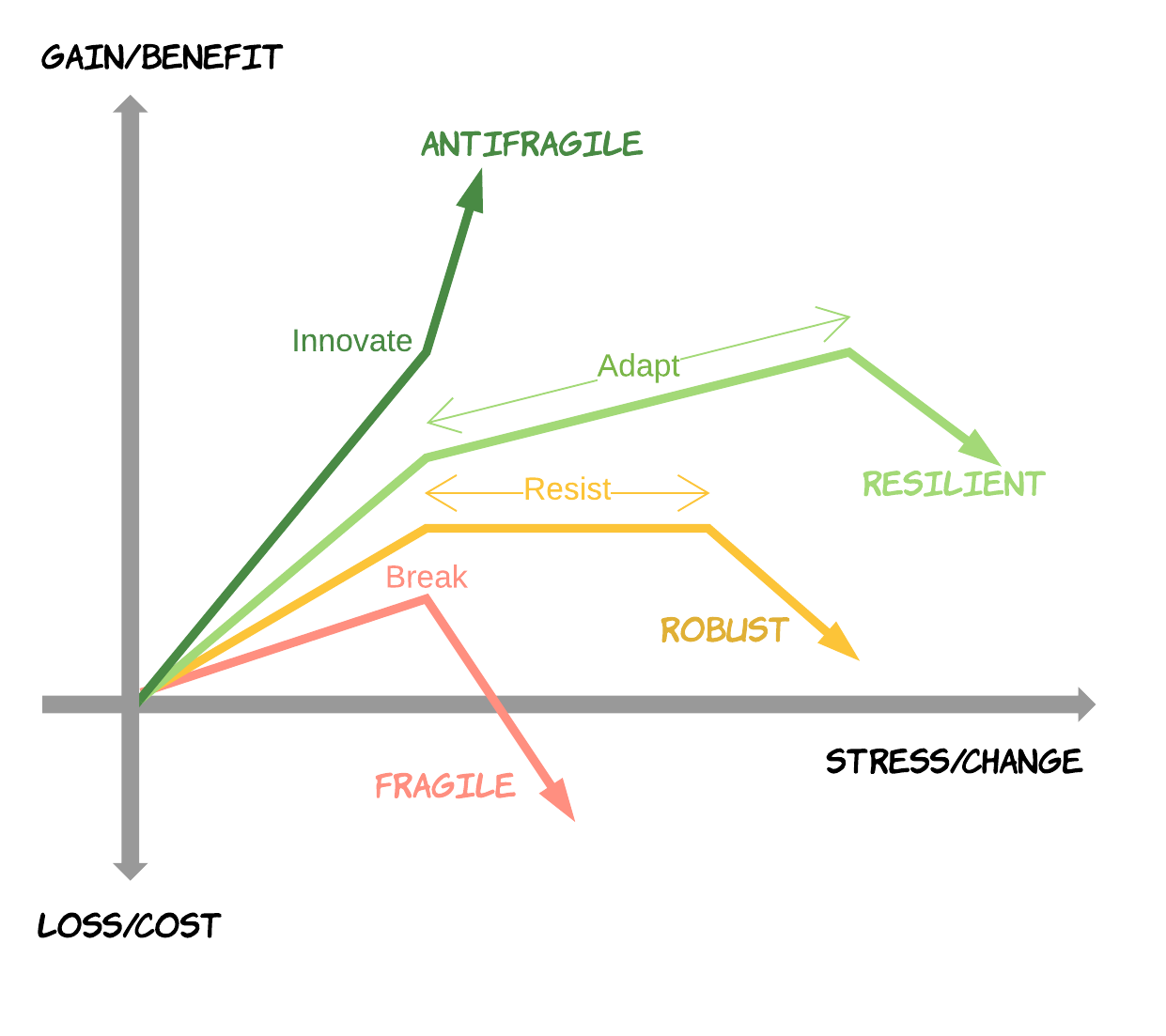
Techniques to improve antifragility
First we need to shock the system. We can do these by using CI/CD as it was intended to. Every code change must go to production. Of course we do need guards against this. Use of fitness functions is a great way to achieve this. The simian army was created with exactly this purpose in mind.
Upgradeability
The ability of a system to seamlessly upgrade itself. This is easily achievable to non-web products (eg app store, google play). The support for this is embedded in the OS. When it comes to web apps things get tricky.
Techniques to improve upgradeability
In order to upgrade firstly we need to give versions to our services. The next step is to use deployment tactics like blue-green or canary to do a zero downtime deployment.
Legal
It is vital that we have the legal right to use any of the 3rd party tools and frameworks which we may need. We must keep an eye here on the open source ones which may come with additional constraint that we do not want. No one want to disclose the source code so we should stay away from GPL licences. Now in the EU GDPR has become mandatory, so we need to make sure we do satisfy it. Does the company needs to follow some processes in order to be some ISO standard complaint?

Techniques to improve legal
Ideally every company should have a legal department. However this is not the case. Again the use of a fitness function (eg license check) will protect us from blacklisted licences. When designing the system we must consider a way to anonymise our users data.
Cost
One of the most important characteristic, if not the most. Everything has a cost, material or not. No matter the type it always translates into money. If we need a buy a license for some our tools (IDE), cloud services(eg aws), 3rd party frameworks (eg new-relic) it will always come with a financial cost. The development team comes also with a cost. Learning new tech or training team members come with a cost. Not respecting the agile manifesto comes with a cost. Bad code comes with a cost. Lack of unit tests come with a cost. Lack of CI/CD comes with a cost. Lack of infrastructure-as-code comes with a cost. The list could go on and on. No wonder our clients are scared and want to reduce it.
Techniques to reduce cost
It is our fiduciary responsibility to help our clients to control the costs. Our role is to differentiate between costs that are just costs and investments. And convince the client that the investments are worth doing.
Take for example the scrum process. Now I’m not saying that it does not work. I’m just saying that I didn’t personally see it working. So many ceremonies (grooming, planning, standups, demos, retros) during a fixed cycle(usually two weeks). Then calculate burnout, velocity and plan based on estimations(which are guesses). Sprints completed 100% represents the exception, not the rule. I need to always refer to the ceremony vs essence comparison. We need to be agile and adapt, not follow blindly the processes. I am an adept of NoEstimates and Scrumban if you want. Reduce meeting minutes and ceremonies and the cost will go down. Focus on essence which is getting stuff done.
Tests are necessary. The only way to go fast is to go right. These are investments. We must convince our clients that costs will go down on the long term. This will reduce the number of bugs, hence the cost.
Code quality is another investment. A code that is good will lead to better tests. It will improve the robustness, maintainability, modifiability and so on. Any change that we make will take much less time than is a system that is hard to maintain. Costs will go down.
Archivability
Refers to the system ability to keep historical data records. It’s important in systems where data is first class citizen(eg financial systems). The data is never deleted but archived, mostly for legal reasons. Archivability acts as a support for auditability.
Techniques to implement archivability
First are foremost use timestamps on the data.(eg updatedOn, createdOn). Then have a cron job that will move all data below a certain threshold into historical tables. Another technique is to mark the data as soft deleted, but this will affect query performance.
Auditability/Tracebility
The system characteristic that permits to reconstitute history. All critical actions must be logged, especially in security scenarios so that we can reproduce issues and learn from mistakes. Also we can use it a legal base if such problem exists.

Techniques to implement auditability
Log every critical action and centralize the logs. ELK will help you in this case. Or the combination of sleuth and zipkin.
PS. This is not a complete list in any way.

1 thought on “Introduction to Architecture characteristics”